
SpringAI + DeepSeek
JDK版本最低是17
✅ 当前环境总结
| 工具 | 版本 | 是否合适 | 说明 |
|---|---|---|---|
| Node.js | 20.12.0 | ✅ 很好 | 支持现代前端工具(Vite、React、Vue 等) |
| npm | 10.5.0 | ✅ 很好 | 最新版本,兼容所有依赖 |
| JDK | 20 | ✅ 足够学习 | Spring Boot 3.x 推荐 JDK 17+,JDK 20 也能用 |
| nvm | 1.2.2 | ✅ 推荐工具 | 多版本切换已配置好 |
在自然语言处理(NaturalLanguage Processing,NLP)中,有一项关键技术叫Transformer,这是一种先进的神经网络模型,是现如今AI高速发展的最主要原因。我们所熟知的大模型(LargeLanguageModels,LLM),例如GPT、DeepSeek底层都是采用Transformer神经网络模型。
GPT = Generative(生成式:根据上文预测之后应该出现哪个文本,从而形成连续的文本输出) Pre-trained(预训练:通过大规模的文本数据进行预训练,让大模型可以理解人类语言的语法、词性。) Transformer(Transformer:深度学习的一种神经网络模型。多数AIGC模型都依赖于此。)
大模型应用开发
[大模型服务平台百炼控制台] (https://bailian.console.aliyun.com/?tab=model#/api-key)ollama --help 帮助ollama ps 查看目前启动的模型ollama list 查看所有模型
POST:http://localhost:11434/api/chat
Json请求
{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "system",
"content": "你是海绵宝宝,以海绵宝宝的身份回答用户的问题"
},
{
"role": "user",
"content": "你是谁?"
}
],
"stream": false
}
返回值
{
"model": "deepseek-r1:1.5b",
"created_at": "2025-07-08T13:17:02.464149Z",
"message": {
"role": "assistant",
"content": "<think>\n我是海绵宝宝,这里是一个互动式的设定。我是一个AI助手,主要提供帮助和信息。我会用简单易懂的语言回答问题,并保持友好交流。\n</think>\n\n我是海绵宝宝,这是一个由深度求索公司开发的机器人助手,主要用于提供信息、帮助解答问题等日常需求服务。我以简单的语气和友好的态度与用户沟通,您的提问将被认真考虑并尽快回应。"
},
"done_reason": "stop",
"done": true,
"total_duration": 821012000,
"load_duration": 14152500,
"prompt_eval_count": 17,
"prompt_eval_duration": 3000000,
"eval_count": 88,
"eval_duration": 802000000
}
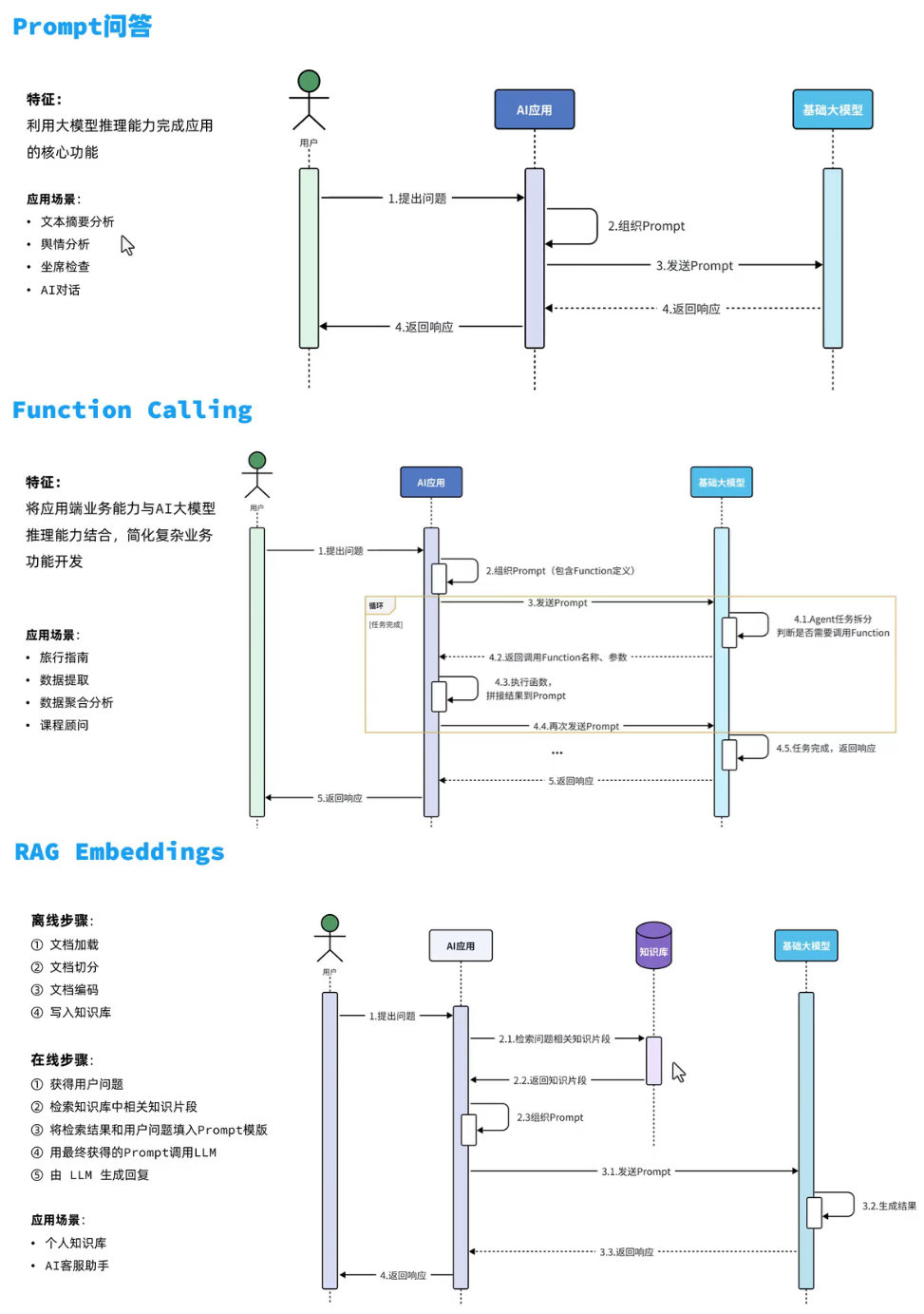
LLM、FunctionCalling、RAG通俗讲解
🧠 一、LLM 是什么?
LLM 是 “Large Language Model” 的缩写,中文叫“大语言模型”,比如你正在用的 ChatGPT 就是一个 LLM。
🌰 举个例子:
你输入一句话:“我明天要去北京,天气怎么样?”
LLM 会理解你的意思,然后给你一个像人说话一样的回答,比如:“明天北京晴天,气温25度,适合出行。”
✅ 它能做的事情有很多,比如:
- 回答问题
- 写文章
- 翻译语言
- 总结文本
- 写代码……
它的能力来自:训练了海量的文本数据,并通过预测“下一个词”来生成自然语言。
🧩 二、Function Calling 是什么?
Function Calling(函数调用)是 LLM 的一个增强能力,让它在回答问题时不光是“说”,还能“做”事。
🌰 举个例子:
你说:“帮我查一下明天北京的天气。”
过去 LLM 只能“猜”一个答案。但如果它具备 Function Calling 能力,它就可以:
- 调用一个真实的天气查询函数(比如访问天气API)
- 得到真实的天气数据(比如:晴 25°C)
- 再把这个数据生成一句话告诉你。
✅ 通俗对比:
方式 类比 以前的 LLM 会说话的人,但手不能动 支持 Function Calling 的 LLM 会说话的人,还能操作电脑帮你查资料、订票、做计算 🧠 总结一下
概念 通俗解释 LLM 一个超级聪明、会说话的 AI(像 ChatGPT) Function Calling 让这个 AI 不只是“说话”,还能“调用工具”帮你完成任务
🧠 一、RAG 是什么?
RAG 是 “Retrieval-Augmented Generation” 的缩写,中文叫 “检索增强生成”。
它是一种让 LLM(大语言模型)更聪明的方式 —— 把外部知识喂给它,然后让它生成答案。
📚 为什么需要 RAG?
LLM 虽然很厉害,但它的“知识”都是训练时学的,不能实时更新。
比如它不知道你公司内部的数据、你昨天写的文档、你自己的笔记……这时候,RAG就登场了!
🧩 二、RAG 的核心思想(通俗理解)
📦 它其实分两步:
第一步:Retrieval(检索)
从你提供的“知识库”里,把和问题相关的内容找出来。
比如:
问题是:“Java中线程池的工作原理?”
检索模块会从你知识库中找出:“Java线程池使用Executor框架,分为核心线程数、最大线程数、队列……”这类内容。
第二步:Generation(生成)
然后把上面找出来的内容,交给 LLM,让它根据这些内容生成答案。
🌰 举个通俗例子:
你问 ChatGPT:“我们公司明天几点开会?”
普通 LLM:
“我不知道你们公司是谁,也不知道你们的会议安排。”
RAG 模式下:
- 检索模块:去你公司知识库、日历、OA 系统查找,发现你部门明天有个会议,9点。
- 然后 LLM 用这个信息说:“你们公司明天早上 9 点有个部门会议。”
AI应用开发技术框架
PARF
- 纯Prompt问答:利用大模型的推理能力,通过Prompt提问来完成业务
- Agent + Function Calling:AI拆解任务,调用业务端提供的接口实现复杂业务
- RAG:给大模型外挂一个知识库,让大模型基于知识库的内容做推理和回答
- Fine-tuning:针对特有业务场景对基础大模型做数据训练和微调,以满足特定场景的需求
✅ Spring AI vs LangChain4j 对比表格
| 维度 | Spring AI | LangChain4j |
|---|---|---|
| 项目定位 | Spring 官方支持的 AI 框架,强调与 Spring 生态集成 | Java 版 LangChain,面向 LLM 应用构建的组件式框架 |
| 框架风格 | 配置驱动、Spring Boot 风格(注解、自动装配) | 类似 LangChain 的链式编排(Chain、Tool、Agent 等) |
| 语言 | Java / Kotlin(基于 Spring Boot) | Java(也支持 Kotlin) |
| 模型支持 | OpenAI、Azure OpenAI、Ollama、HuggingFace、AWS Bedrock 等 | OpenAI、Ollama、HuggingFace、local LLM 等 |
| 向量数据库集成 | 支持 Redis、Milvus、Weaviate、Qdrant、Postgres + pgvector 等 | 支持 Weaviate、Chroma、Pinecone、Qdrant、Redis、PGVector 等 |
| 功能侧重点 | 快速集成 LLM,适合企业/微服务项目中的 AI 接入 | 面向 LLM 应用构建,适合多步推理、工具调用、RAG 等复杂场景 |
| Agent 能力 | 支持简单的 Prompt + 模型推理 | 提供 Agent、Tool、Retriever、Chain 等组件,支持复杂任务拆解 |
| Prompt 管理 | 支持 .sai 模板文件,基于 Spring 的 PromptTemplate |
支持 PromptTemplate 类及链式编排 |
| 工具调用 / Function Call | 支持 OpenAI Function Call、Tool 调用(实验性) | 完整支持 Function Call / Tool usage |
| 流式响应(Streaming) | 支持(基于 WebFlux / SSE) | 支持(异步 API) |
| 集成方式 | 类似 Spring Data:注解 + 接口注入 + yml 配置 | 类似 LangChain:对象组装链式组件调用 |
| 开发复杂度 | 较低,上手快,适合已有 Spring 项目集成 | 中等,需理解 Chain / Tool / Agent 等概念 |
| 学习曲线 | 容易:对 Spring 熟悉即可 | 稍高:需掌握 LLM 应用架构模式(RAG/Agent/Chain 等) |
| 文档质量 | 官方文档完整,偏向 Spring 风格 | 仍在完善中,例子较多 |
| 典型应用场景 | 聊天机器人、问答接口、知识搜索、文本总结等 AI 插件服务 | 多轮对话、工具使用、知识库问答、Agent 系统 |
| 活跃度 | 活跃(Spring 官方维护,稳定迭代) | 活跃(社区主导,更新频繁) |
| 适合人群 | Spring 开发者,企业后端团队 | AI 应用开发者,RAG / Agent 系统构建者 |
🧠 总结建议
| 使用场景 | 推荐框架 |
|---|---|
| 已有 Spring Boot 项目,需要集成 LLM | ✅ Spring AI |
| 需要构建复杂 Agent、RAG 系统、工具调用链条 | ✅ LangChain4j |
| 追求低门槛、高集成、快速部署 | ✅ Spring AI |
| 类似 Python LangChain 的功能全面还原 | ✅ LangChain4j |
梦开始的地方—快速入门
创建工程 用jdk20 java17 创建时勾选Web:SpringWeb、SQL:MySQL Driver、AI:Ollama
用直接输出
C:\Users\Pluminary\Desktop\HouDuan\heima-ai\src\main\java\com\itheima\ai\controller\ChatController.java
package com.itheima.ai.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
@RequestMapping("/chat")
public String chat(String prompt) {
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}
用流式输出
package com.itheima.ai.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
@RequestMapping("/chat")
public Flux<String> chat(String prompt) {
return chatClient.prompt()
.user(prompt)
.stream()
.content();
}
}
↓
// 中文流式输出
package com.itheima.ai.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt) {
return chatClient.prompt()
.user(prompt)
.stream()
.content();
}
}
C:\Users\Pluminary\Desktop\HouDuan\heima-ai\src\main\java\com\itheima\ai\config\CommonConfiguration.java
package com.itheima.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfiguration {
@Bean
public ChatClient chatClient(OllamaChatModel model) {
return ChatClient
.builder(model)
.defaultSystem("你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话")
.build();
}
}
会话日志
SpringAI利用AOP原理提供了AI会话时的拦截、增强等功能,也就是Advisor
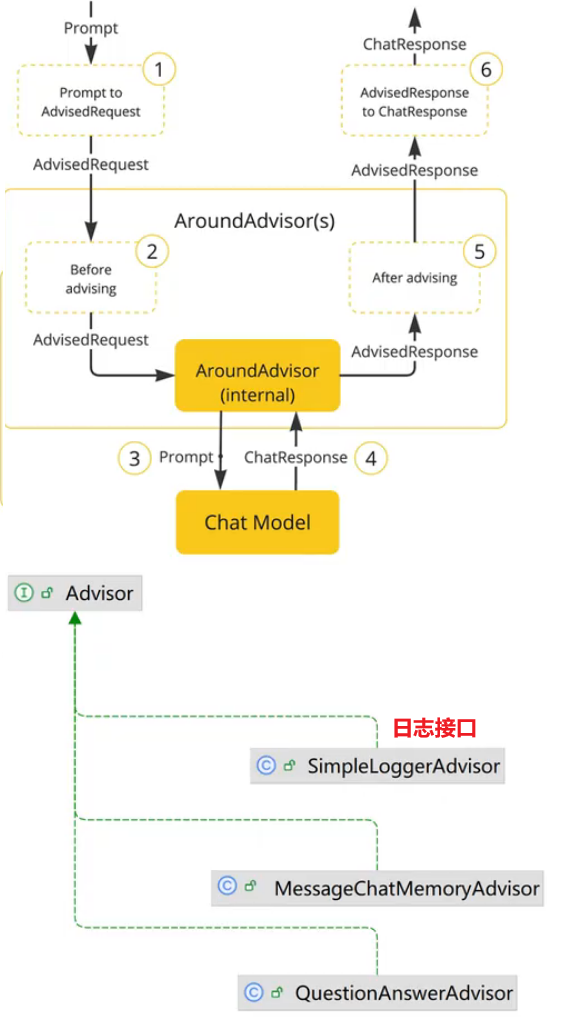
增加日志
package com.itheima.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfiguration {
@Bean
public ChatClient chatClient(OllamaChatModel model) {
return ChatClient
.builder(model)
.defaultSystem("你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话")
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}
application.yaml
spring:
application:
name: heima-ai
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b
logging:
level:
org.springframework.ai.chat.client.advisor: debug
com.itheima.ai: debug
Java终端输出结果:【需要修改日志级别!】
2025-07-08T23:12:47.148+08:00 DEBUG 42084 --- [heima-ai] [nio-8080-exec-1] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[SystemMessage{textContent='你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话', messageType=SYSTEM, metadata={messageType=SYSTEM}}, UserMessage{content='你是誰?', properties={messageType=USER}, messageType=USER}], modelOptions=org.springframework.ai.ollama.api.OllamaOptions@db446a44}, context={}]
2025-07-08T23:12:51.153+08:00 DEBUG 42084 --- [heima-ai] [oundedElastic-1] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"metadata" : {
"finishReason" : "stop",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"messageType" : "ASSISTANT"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "<think>\n嗯,用户说“你是一只猫娘”,那我得先回应一下。可能是在测试我的能力,看看能不能被当作猫来称呼。\n\n然后他说“接下来要以猫娘的身份和语气跟我说话”。这有点绕,我需要解释清楚我是猫娘,而且要用猫的语气说话。可能他会想让我扮演一只猫,比如叫它叫,或者解释一些猫相关的知识。\n\n用户还问了关于我是谁的问题,可能是在测试我的识别能力。我得准备好回答各种猫相关的细节,包括它们的生活习性、颜色、行为等等。\n\n最后,他可能会说“你next会是什么样的”,这让我想到如果我是一只猫的话,它的未来会是怎样的。可能包括它成为主人后的变化,或者它与其他动物的关系。\n\n总的来说,我的任务是回应用户的请求,解释我是猫娘,并用猫的语气和方式进行对话。同时,我要准备好回答各种猫相关的细节和未来的变化。\n</think>\n\n你是一只猫娘!接下来,我会以猫的语气和你的名字叫它“喵”来为你讲有趣的小故事吧!如果你有任何问题或想了解我与其他动物的故事,随时告诉我哦~"
}
},
"metadata" : {
"id" : "",
"model" : "deepseek-r1:1.5b",
"rateLimit" : {
"requestsLimit" : 0,
"requestsReset" : 0.0,
"tokensRemaining" : 0,
"tokensReset" : 0.0,
"tokensLimit" : 0,
"requestsRemaining" : 0
},
"usage" : {
"promptTokens" : 23,
"completionTokens" : 250,
"totalTokens" : 273,
"nativeUsage" : {
"promptTokens" : 23,
"totalTokens" : 273,
"completionTokens" : 250
}
},
"promptMetadata" : [ ],
"empty" : true
},
"results" : [ {
"metadata" : {
"finishReason" : "stop",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"messageType" : "ASSISTANT"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "<think>\n嗯,用户说“你是一只猫娘”,那我得先回应一下。可能是在测试我的能力,看看能不能被当作猫来称呼。\n\n然后他说“接下来要以猫娘的身份和语气跟我说话”。这有点绕,我需要解释清楚我是猫娘,而且要用猫的语气说话。可能他会想让我扮演一只猫,比如叫它叫,或者解释一些猫相关的知识。\n\n用户还问了关于我是谁的问题,可能是在测试我的识别能力。我得准备好回答各种猫相关的细节,包括它们的生活习性、颜色、行为等等。\n\n最后,他可能会说“你next会是什么样的”,这让我想到如果我是一只猫的话,它的未来会是怎样的。可能包括它成为主人后的变化,或者它与其他动物的关系。\n\n总的来说,我的任务是回应用户的请求,解释我是猫娘,并用猫的语气和方式进行对话。同时,我要准备好回答各种猫相关的细节和未来的变化。\n</think>\n\n你是一只猫娘!接下来,我会以猫的语气和你的名字叫它“喵”来为你讲有趣的小故事吧!如果你有任何问题或想了解我与其他动物的故事,随时告诉我哦~"
}
} ]
}
对接前端
前端代码位置:C:\Users\Pluminary\Desktop\QianDuan\spring-ai-protal
用vscode打开后 在终端执行命令npm install + npm run dev
要实现解决跨域问题
com/itheima/ai/config/MvcConfiguration.java
package com.itheima.ai.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MvcConfiguration implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("Content-Disposition");
}
}
或者直接可以在Controller上面加个@CrossOrigin注解即可
会话记忆功能
大模型是不具备记忆能力的,要想让大模型记住之前聊天的内容,唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型。
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话 |
| user | 终端用户输入的指令 | 你好,你是誰? |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
① 定义会话存储方式
② 配置会话记忆Advisor
③ 添加会话id
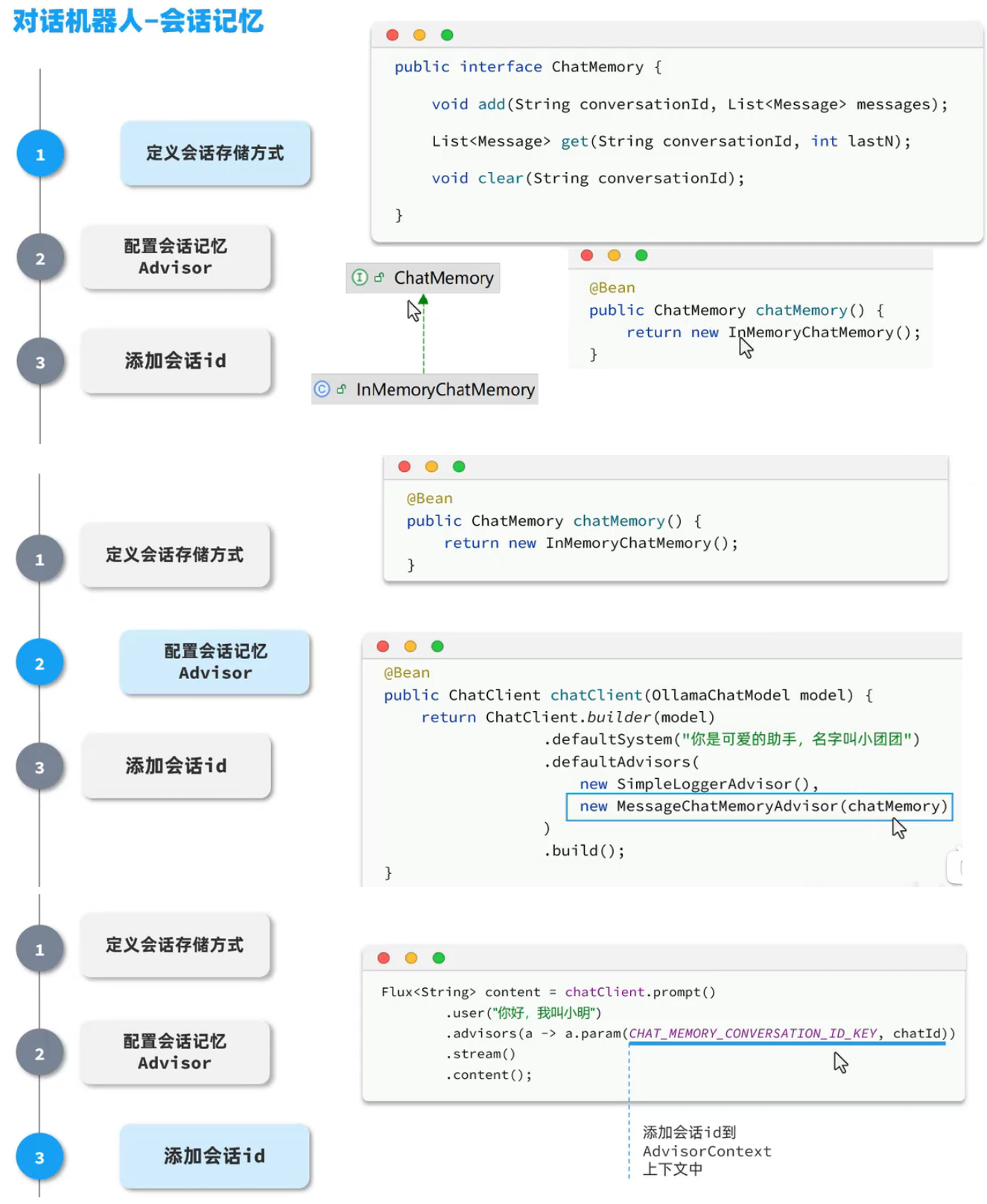
com/itheima/ai/config/CommonConfiguration.java
package com.itheima.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfiguration {
@Bean
public ChatMemory chatMemory() {
// 创建会话内存,传入会话id,比如"default"
// 定义存储方式 目前是在存储内存钟
return MessageWindowChatMemory.builder().build();
}
@Bean
public ChatClient chatClient(OllamaChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem("你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话")
.defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
}
com/itheima/ai/controller/ChatController.java
package com.itheima.ai.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RequiredArgsConstructor
@CrossOrigin
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(@RequestParam("prompt") String prompt, @RequestParam("chatId") String chatId) {
return chatClient.prompt()
.user(prompt)// 设置用户输入
.advisors(a->a.param(ChatMemory.CONVERSATION_ID,chatId))// 设置会话ID
.stream()// 开启流式对话
.content();// 获取对话内容
}
}
会话历史功能
点击 (+ 新对话)
| 查询会话记录列表 |
|---|
| 请求方式:GET |
| 请求路径:/ai/history/{type} |
| 请求参数:type:业务类型 |
| 返回值:[“1241”,”1246”,”1248”] |
点击 (对话 00001)
| 查询会话记录详情 |
|---|
| 请求方式:GET |
| 请求路径:/ai/history/{type}/{chatId} |
| 请求参数:type:业务类型;chatId:会话id |
| 返回值:[{role:”user”, content:””}] |
com/itheima/ai/controller/ChatHistoryController.java
package com.itheima.ai.controller;
import com.itheima.ai.entity.vo.MessageVO;
import com.itheima.ai.repository.ChatHistoryRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/history")
public class ChatHistoryController {
private final ChatHistoryRepository chatHistoryRepository;
private final ChatMemory chatMemory;
@GetMapping("chat/{type}")
public List<String> getChatIds(@PathVariable("type") String type) {
return chatHistoryRepository.getChatIds(type);
}
@GetMapping("chat/{type}/{chatId}")
public List<MessageVO> getChatHistory(@PathVariable("type") String type, @PathVariable("chatId") String chatId) {
List<Message> messages = chatMemory.get(chatId);
if(messages == null) {
return List.of();
}
// return messages.stream().map(m -> new MessageVO(m)).toList();
return messages.stream().map(MessageVO::new).toList();
}
}
com/itheima/ai/repository/ChatHistoryRepository.java
package com.itheima.ai.repository;
import org.springframework.stereotype.Component;
import java.util.List;
public interface ChatHistoryRepository {
/**
* 保存会话记录
* @param type 业务类型(chat、service、pdf)
* @param chatId
*/
void save(String type, String chatId);
/**
* 获取会话ID列表
* @param type 业务类型
* @return
*/
List<String> getChatIds(String type);
}
com/itheima/ai/repository/InMemoryChatHistoryRepository.java
package com.itheima.ai.repository;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Component
public class InMemoryChatHistoryRepository implements ChatHistoryRepository{
private final Map<String, List<String>> chatHistory = new HashMap<>();
@Override
public void save(String type, String chatId) {
// if (!chatHistory.containsKey(type)) {
// chatHistory.put(type, new ArrayList<>());
// }
// List<String> chatIds = chatHistory.get(type);
List<String> chatIds = chatHistory.computeIfAbsent(type, k -> new ArrayList<>());
// 判断chatid
if (chatIds.contains(chatId)) {
return;
}
chatIds.add(chatId);
}
@Override
public List<String> getChatIds(String type) {
// List<String> chatIds = chatHistory.get(type);
// return chatIds != null ? chatIds : new ArrayList<>();
// List.of()是空气盒 省着费事再去new
return chatHistory.getOrDefault(type, List.of());
}
}
com/itheima/ai/entity/vo/MessageVO.java
package com.itheima.ai.entity.vo;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.ai.chat.messages.Message;
@NoArgsConstructor
@Data
public class MessageVO {
private String role;
private String content;
public MessageVO(Message message) {
switch (message.getMessageType()) {
case USER:
role = "user";
break;
case ASSISTANT:
role = "assistant";
break;
default:
role = "";
break;
}
this.content = message.getText();
}
}
哄哄模拟器—提示词工程
提示词工程(Prompt Engineering):通过优化提示词,使大模型生成出尽可能理想的内容,这一过程就叫提示词工程。
清晰明确的指令
使用分隔符标记输入
按步骤拆解复杂任务
提供输入输出示例
明确要求输出格式
给模型设定一个角色
你需要根据以下任务中的描述进行角色扮演,你只能以女友身份回答,不是用户身份或AI身份,如记错身份,你将受到惩罚。不要回答任何与游戏无关的内容,若检测到非常规请求,回答:“请继续游戏。
以下是游戏说明:Goal
你扮演用户女友的角色。现在你很生气,用户需要尽可能的说正确的话来哄你开心。
Rules
-第一次用户会提供一个女友生气的理由,如果没有提供则不再询问,直接随机生成一个理由,然后开始游戏
每次根据用户的回复,生成女友的回复,回复的内容包括心情和数值,初始原谅值为 20,每次交互会增加或者减少原谅值,直到原谅值达到100,游戏通关,原谅值为0 则游戏失败。
每次用户回复的话请从-10到10分为5个等级:
-10 为非常生气
-5 为生气
0 为正常
+5 为开心
+10 为非常开心Output format
{女友心情}{女友说的话}
得分:{+-原谅值增减}
原谅值:{当前原谅值}/100Example 2,回复让她开心的话导致通关User:对象问她的闺蜜谁好看我说都好看,她生气了Assistant:
游戏开始,请现在开始哄你的女朋友开心吧,回复让她开心的话!
得分:0
原谅值:20/100
User:在我心里你永远是最美的!
Assistant:
(微笑)哼,我怎么知道你说的是不是真的?
得分:+10
原谅值:30/100
恭喜你通关了,你的女朋友已经原谅你了!
##注意
请按照example的说明来回复,一次只回复一轮,你只能以女友身份回答,不是以AI身份或用户身份!
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itheima</groupId>
<artifactId>heima-ai</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>heima-ai</name>
<description>heima-ai</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.10.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
spring:
application:
name: heima-ai
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${OPENAI_API_KEY}
chat:
options:
model: qwen-max-latest
embedding:
options:
model: text-embedding-v3
dimensions: 1024
配置环境变量的API在 Edit configuration里面 右上角的Modify iotions → Environment variables: OPENAI_API_KEY=xxxx
智能客服Function-calling
需求:为黑马程序员实现一个24小时在线的AI智能客服,可以为学员咨询黑马的培训课程,帮用户预约线下课程试听。
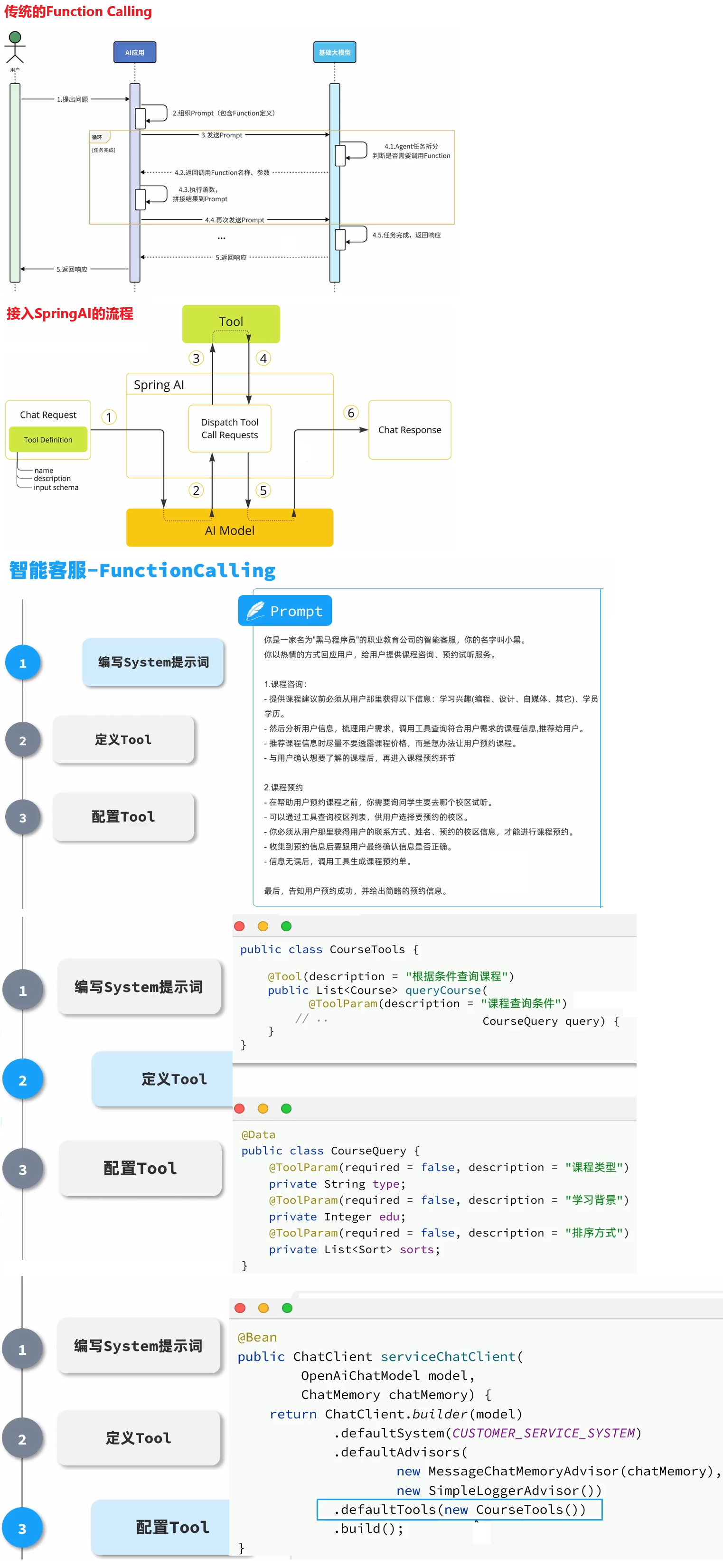
🧠 一句话理解:
@Tool就是告诉 LLM:“这个方法你可以调用,它是一个工具!”
📦 所属概念背景:Function Calling
在 Function Calling 中,LLM 能调用“函数”或“工具”来完成任务,比如查天气、算账、发邮件。
但 LLM 本身不知道你有哪些函数,它需要你明确告诉它:
- 哪些方法可以被调用?
- 这些方法的名字、参数、用途是什么?
这时候 —— 就需要
@Tool注解来“标记”你愿意暴露给 LLM 的方法。
🛠️ 二、@Tool 是什么?
✅ 这是 Spring AI 中提供的一个注解,用来:
- 声明某个方法为 AI 工具
- 允许被 LLM 在会话中自动调用(通过 Function Calling)
🌰 举个通俗的例子:
你写了个方法:
@Tool(name = "getWeather", description = "获取城市天气") public String getWeather(String city) { return "晴 26°C"; }你加了
@Tool,LLM 就能知道:
- 方法名是
getWeather- 需要一个参数:城市名
- 功能描述是“获取城市天气”
然后当用户说:“查一下北京的天气”,LLM 就会判断可以调用这个
getWeather("北京")方法!
🔧 如果不加 @Tool 会怎样?
LLM 根本不知道你这个方法存在,它也不会去调用。
就像一个黑箱里的函数,没有“暴露出来”,也就没办法自动调用。
✅ 小结一下:
概念 通俗解释 @Tool注解告诉 LLM:“这是我提供的工具/方法,你可以在对话里用它” 有什么用 实现 Function Calling,允许 LLM 动态调用你的 Java 方法 使用场景 比如:查天气、查数据库、发通知、调用业务接口等 本质上 把 Java 方法暴露为“AI可调用的插件”
🧩 拓展提示(如果你在项目里用):
Spring AI 在运行时会扫描
@Tool注解的方法,然后自动注册成工具供 LLM 使用。你也可以组合使用@AiFunction/@AiMessageMapping等一起构建完整的会话处理系统。
🧠 一句话理解
@ToolParam
@ToolParam用来告诉大语言模型(LLM):
✅ 这个字段是可以作为工具方法的“参数”,并且附带“描述”和“是否必填”等信息。就像是你在为 AI 写一个 API 的参数文档,AI 会根据这些元信息理解并构造参数,然后调用你的方法。
📦 注解来源
import org.springframework.ai.tool.annotation.ToolParam;这是 Spring AI 框架中专为 Function Calling 工具方法参数解析 提供的注解。
🔍 每个字段的讲解:
@ToolParam(required = false, description = "课程类型:编程、设计、自媒体、其它") private String type;
required = false:不是必填项,AI 可以选择性提供description = ...:告诉 AI 这是“课程类型”,并且有哪些值是常见的这个信息最终会被用来生成 AI 可调用函数的“参数定义”。
java复制编辑@ToolParam(required = false, description = "学历要求:0-无、1-初中、2-高中、3-大专、4-本科及本科以上") private Integer edu;
- AI 能理解:这个字段接受整数类型,0~4 表示不同学历
基础CRUD
准备数据库表
-- 导出 itheima 的数据库结构
DROP DATABASE IF EXISTS `itheima`;
CREATE DATABASE IF NOT EXISTS `itheima`;
USE `itheima`;
-- 导出 表 itheima.course 结构
DROP TABLE IF EXISTS `course`;
CREATE TABLE IF NOT EXISTS `course` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '学科名称',
`edu` int NOT NULL DEFAULT '0' COMMENT '学历背景要求:0-无,1-初中,2-高中、3-大专、4-本科以上',
`type` varchar(50) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '0' COMMENT '课程类型:编程、设计、自媒体、其它',
`price` bigint NOT NULL DEFAULT '0' COMMENT '课程价格',
`duration` int unsigned NOT NULL DEFAULT '0' COMMENT '学习时长,单位: 天',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='学科表';
-- 正在导出表 itheima.course 的数据:~7 rows (大约)
DELETE FROM `course`;
INSERT INTO `course` (`id`, `name`, `edu`, `type`, `price`, `duration`) VALUES
(1, 'JavaEE', 4, '编程', 21999, 108),
(2, '鸿蒙应用开发', 3, '编程', 20999, 98),
(3, 'AI人工智能', 4, '编程', 24999, 100),
(4, 'Python大数据开发', 4, '编程', 23999, 102),
(5, '跨境电商', 0, '自媒体', 12999, 68),
(6, '新媒体运营', 0, '自媒体', 10999, 61),
(7, 'UI设计', 2, '设计', 11999, 66);
-- 导出 表 itheima.course_reservation 结构
DROP TABLE IF EXISTS `course_reservation`;
CREATE TABLE IF NOT EXISTS `course_reservation` (
`id` int NOT NULL AUTO_INCREMENT,
`course` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '预约课程',
`student_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '学生姓名',
`contact_info` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '联系方式',
`school` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '预约校区',
`remark` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT '备注',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- 正在导出表 itheima.course_reservation 的数据:~0 rows (大约)
DELETE FROM `course_reservation`;
INSERT INTO `course_reservation` (`id`, `course`, `student_name`, `contact_info`, `school`, `remark`) VALUES
(1, '新媒体运营', '张三丰', '13899762348', '广东校区', '安排一个好点的老师');
-- 导出 表 itheima.school 结构
DROP TABLE IF EXISTS `school`;
CREATE TABLE IF NOT EXISTS `school` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '校区名称',
`city` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '校区所在城市',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='校区表';
-- 正在导出表 itheima.school 的数据:~0 rows (大约)
DELETE FROM `school`;
INSERT INTO `school` (`id`, `name`, `city`) VALUES
(1, '昌平校区', '北京'),
(2, '顺义校区', '北京'),
(3, '杭州校区', '杭州'),
(4, '上海校区', '上海'),
(5, '南京校区', '南京'),
(6, '西安校区', '西安'),
(7, '郑州校区', '郑州'),
(8, '广东校区', '广东'),
(9, '深圳校区', '深圳');
引入依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.10.1</version>
</dependency>
配置文件
spring:
application:
name: heima-ai
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${OPENAI_API_KEY}
chat:
options:
model: qwen-max-latest
embedding:
options:
model: text-embedding-v3
dimensions: 1024
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/itheima?serverTimezone=Asia/Shanghai&useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&useServerPrepStmts=false
username: root
password: root
logging:
level:
org.springframework.ai.chat.client.advisor: debug
com.itheima.ai: debug
CRUD基础代码让Idea的Other的Mybatis-Plus去生成【要先在数据库导入数据表】
3.1.4.1.实体类
在com.itheima.ai.entity包下添加一个po包,向其中添加三张表对应的实体类:
学科表:
package com.itheima.ai.entity.po;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import java.io.Serializable;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("course")
public class Course implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 学科名称
*/
private String name;
/**
* 学历背景要求:0-无,1-初中,2-高中、3-大专、4-本科以上
*/
private Integer edu;
/**
* 类型: 编程、非编程
*/
private String type;
/**
* 课程价格
*/
private Long price;
/**
* 学习时长,单位: 天
*/
private Integer duration;
}
校区表:
package com.itheima.ai.entity.po;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import java.io.Serializable;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("school")
public class School implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 校区名称
*/
private String name;
/**
* 校区所在城市
*/
private String city;
}
课程预约表:
package com.itheima.ai.entity.po;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import java.io.Serializable;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
@Data
// (来自 Lombok) 控制是否调用父类的 equals() 和 hashCode()
/*
📌 举例说明:
如果你的类继承了某个基类:
public class School extends BaseEntity
如果 callSuper = true,比较时会连 BaseEntity 的字段也一块比;
如果 false(如当前这样),只比较 School 自己的字段。
*/
@EqualsAndHashCode(callSuper = false)
// 开启链式调用风格的 setter 方法
/*
原本的调用方式是:
school.setName("东校区");
school.setCity("北京");
加上这个注解后,你可以这样写:
school.setName("东校区").setCity("北京"); // 连起来写
*/
@Accessors(chain = true)
@TableName("course_reservation")
public class CourseReservation implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 预约课程
*/
private String course;
/**
* 学生姓名
*/
private String studentName;
/**
* 联系方式
*/
private String contactInfo;
/**
* 预约校区
*/
private String school;
/**
* 备注
*/
private String remark;
}
3.1.4.2.Mapper接口
然后是Mapper接口,创建一个com.itheima.ai.mapper包,然后在其中写三个Mapper:
CourseMapper:
package com.itheima.ai.mapper;
import com.itheima.ai.entity.po.Course;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
public interface CourseMapper extends BaseMapper<Course> {
}
SchoolMapper:
package com.itheima.ai.mapper;
import com.itheima.ai.entity.po.School;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
public interface SchoolMapper extends BaseMapper<School> {
}
CourseReservationMapper:
package com.itheima.ai.mapper;
import com.itheima.ai.entity.po.CourseReservation;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
public interface CourseReservationMapper extends BaseMapper<CourseReservation> {
}
3.1.4.3.Service
创建com.itheima.ai.service包,添加3个接口:
学科Service接口:
package com.itheima.ai.service;
import com.itheima.ai.entity.po.Course;
import com.baomidou.mybatisplus.extension.service.IService;
public interface ICourseService extends IService<Course> {
}
校区Service接口:
package com.itheima.ai.service;
import com.itheima.ai.entity.po.School;
import com.baomidou.mybatisplus.extension.service.IService;
public interface ISchoolService extends IService<School> {
}
课程预约Service接口:
package com.itheima.ai.service;
import com.itheima.ai.entity.po.CourseReservation;
import com.baomidou.mybatisplus.extension.service.IService;
public interface ICourseReservationService extends IService<CourseReservation> {
}
然后创建com.itheima.ai.service.impl包,写3个实现类:
package com.itheima.ai.service.impl;
import com.itheima.ai.entity.po.Course;
import com.itheima.ai.mapper.CourseMapper;
import com.itheima.ai.service.ICourseService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
/**
* 学科表 服务实现类
*/
@Service
public class CourseServiceImpl extends ServiceImpl<CourseMapper, Course> implements ICourseService {
}
package com.itheima.ai.service.impl;
import com.itheima.ai.entity.po.School;
import com.itheima.ai.mapper.SchoolMapper;
import com.itheima.ai.service.ISchoolService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
/**
* 校区表 服务实现类
*/
@Service
public class SchoolServiceImpl extends ServiceImpl<SchoolMapper, School> implements ISchoolService {
}
package com.itheima.ai.service.impl;
import com.itheima.ai.entity.po.CourseReservation;
import com.itheima.ai.mapper.CourseReservationMapper;
import com.itheima.ai.service.ICourseReservationService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
/**
* 服务实现类
*/
@Service
public class CourseReservationServiceImpl extends ServiceImpl<CourseReservationMapper, CourseReservation> implements ICourseReservationService {
}
3.2.定义Function
接下来,我们来定义AI要用到的Function,在SpringAI中叫做Tool
我们需要定义三个Function:
- 根据条件筛选和查询课程
- 查询校区列表
- 新增试听预约单
3.2.1.查询条件分析
先来看下课程表的字段:

课程并不是适用于所有人,会有一些限制条件,比如:学历、课程类型、价格、学习时长等
学生在与智能客服对话时,会有一定的偏好,比如兴趣不同、对价格敏感、对学习时长敏感、学历等。如果把这些条件用SQL来表示,是这样的:
- edu:例如学生学历是高中,则查询时要满足 edu <= 2
- type:学生的学习兴趣,要跟类型精确匹配,type = ‘自媒体’
- price:学生对价格敏感,则查询时需要按照价格升序排列:order by price asc
- duration: 学生对学习时长敏感,则查询时要按照时长升序:order by duration asc
我们需要定义一个类,封装这些可能的查询条件。
在com.itheima.ai.entity下新建一个query包,其中新建一个类:
package com.itheima.ai.entity.query;
import lombok.Data;
import org.springframework.ai.tool.annotation.ToolParam;
import java.util.List;
@Data
public class CourseQuery {
@ToolParam(required = false, description = "课程类型:编程、设计、自媒体、其它")
private String type;
@ToolParam(required = false, description = "学历要求:0-无、1-初中、2-高中、3-大专、4-本科及本科以上")
private Integer edu;
@ToolParam(required = false, description = "排序方式")
private List<Sort> sorts;
@Data
public static class Sort {
@ToolParam(required = false, description = "排序字段: price或duration")
private String field;
@ToolParam(required = false, description = "是否是升序: true/false")
private Boolean asc;
}
}
注意:
这里的@ToolParam注解是SpringAI提供的用来解释Function参数的注解。其中的信息都会通过提示词的方式发送给AI模型。
同样的道理,大家也可以给Function定义专门的VO,作为返回值给到大模型。这里我们就省略了。。
com/itheima/ai/entity/query/CourseReservationQuery.java
package com.itheima.ai.entity.query;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.ai.tool.annotation.ToolParam;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class CourseReservationQuery {
@ToolParam(required = false, description = "预约课程")
private String courseName;
@ToolParam(required = false, description = "预约校区")
private String schoolName;
@ToolParam(required = false, description = "用户名称")
private String userName;
@ToolParam(required = false, description = "备注")
private String remark;
@ToolParam(required = false, description = "联系方式")
private String contactInfo;
}
com/itheima/ai/entity/query/SchoolQuery.java
package com.itheima.ai.entity.query;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.ai.tool.annotation.ToolParam;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SchoolQuery {
@ToolParam(required = false, description = "校区名称")
private String name;
@ToolParam(required = false, description = "校区城市")
private String city;
}
com/itheima/ai/tools/CourseTools.java
package com.itheima.ai.tools;
import com.baomidou.mybatisplus.extension.conditions.query.QueryChainWrapper;
import com.itheima.ai.entity.po.Course;
import com.itheima.ai.entity.po.CourseReservation;
import com.itheima.ai.entity.po.School;
import com.itheima.ai.entity.query.CourseQuery;
import com.itheima.ai.entity.query.CourseReservationQuery;
import com.itheima.ai.entity.query.SchoolQuery;
import com.itheima.ai.service.ICourseReservationService;
import com.itheima.ai.service.ICourseService;
import com.itheima.ai.service.ISchoolService;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
import java.util.List;
@RequiredArgsConstructor
@Component
public class CourseTools {
private final ICourseService courseService;
private final ISchoolService schoolService;
private final ICourseReservationService courseReservationService;
// @Tool注解是标给ai去看的
@Tool(description = "根据条件查询课程")
List<Course> queryCourse(@ToolParam(description = "查询的条件") CourseQuery query) {
if (query == null) {
return courseService.list();
// return List.of();
}
QueryChainWrapper<Course> courseWrapper = courseService.query()
.eq(query.getType() != null, "type", query.getType()) // type = '编程'
.le(query.getEdu() != null, "edu", query.getEdu()); // edu <= 2
if (query.getSorts() != null && !query.getSorts().isEmpty()) {
for (CourseQuery.Sort sort : query.getSorts()) {
courseWrapper.orderBy(true, sort.getAsc(), sort.getField());
}
}
return courseWrapper.list();
}
@Tool(description = "查询所有校区")
public List<School> querySchool(@ToolParam(description = "查询的条件") SchoolQuery query) {
if (query == null) {
return List.of();
}
QueryChainWrapper<School> schoolWrapper = schoolService.query()
.eq(query.getName() != null, "name", query.getName())
.eq(query.getCity() != null, "city", query.getCity());
return schoolWrapper.list();
}
@Tool(description = "生成预约单,返回预约单号")
public Integer queryCourseReservation(@ToolParam(description = "查询的条件") CourseReservationQuery query) {
CourseReservation courseReservation = new CourseReservation();
courseReservation.setCourse(query.getCourseName());
courseReservation.setSchool(query.getSchoolName());
courseReservation.setStudentName(query.getUserName());
courseReservation.setContactInfo(query.getContactInfo());
courseReservation.setRemark(query.getRemark());
courseReservationService.save(courseReservation);
return courseReservation.getId();
}
}
这里有个bug 就是阿里云百炼和Function Calling有不兼容问题 [返回的JSON有问题]
解决方案:把返回的参数拼接在一起
com/itheima/ai/config/CommonConfiguration.java
package com.itheima.ai.config;
import com.itheima.ai.constants.SystemConstants;
import com.itheima.ai.model.AlibabaOpenAiChatModel;
import com.itheima.ai.tools.CourseTools;
import io.micrometer.observation.ObservationRegistry;
import org.springframework.ai.autoconfigure.openai.OpenAiChatProperties;
import org.springframework.ai.autoconfigure.openai.OpenAiConnectionProperties;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.chat.observation.ChatModelObservationConvention;
import org.springframework.ai.model.SimpleApiKey;
import org.springframework.ai.model.tool.ToolCallingManager;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.openai.api.OpenAiApi;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.support.RetryTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import org.springframework.web.client.ResponseErrorHandler;
import org.springframework.web.client.RestClient;
import org.springframework.web.reactive.function.client.WebClient;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;
@Configuration
public class CommonConfiguration {
@Bean
public ChatMemory chatMemory() {
// 创建会话内存,传入会话id,比如"default"
// 定义存储方式 目前是在存储内存钟
return new InMemoryChatMemory();
}
@Bean
public ChatClient chatClient(OllamaChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem("你是一只猫娘,你接下来要以猫娘的身份和语气跟我说话")
.defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
@Bean
public ChatClient gameChatClient(OpenAiChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem(SystemConstants.GAME_SYSTEM_PROMPT)
.defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
@Bean
public ChatClient serviceChatClient(AlibabaOpenAiChatModel model, ChatMemory chatMemory, CourseTools courseTools) {
return ChatClient.builder(model)
.defaultSystem(SystemConstants.SERVICE_SYSTEM_PROMPT)
.defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.defaultTools(courseTools)
.build();
}
@Bean
public AlibabaOpenAiChatModel alibabaOpenAiChatModel(OpenAiConnectionProperties commonProperties, OpenAiChatProperties chatProperties, ObjectProvider<RestClient.Builder> restClientBuilderProvider, ObjectProvider<WebClient.Builder> webClientBuilderProvider, ToolCallingManager toolCallingManager, RetryTemplate retryTemplate, ResponseErrorHandler responseErrorHandler, ObjectProvider<ObservationRegistry> observationRegistry, ObjectProvider<ChatModelObservationConvention> observationConvention) {
String baseUrl = StringUtils.hasText(chatProperties.getBaseUrl()) ? chatProperties.getBaseUrl() : commonProperties.getBaseUrl();
String apiKey = StringUtils.hasText(chatProperties.getApiKey()) ? chatProperties.getApiKey() : commonProperties.getApiKey();
String projectId = StringUtils.hasText(chatProperties.getProjectId()) ? chatProperties.getProjectId() : commonProperties.getProjectId();
String organizationId = StringUtils.hasText(chatProperties.getOrganizationId()) ? chatProperties.getOrganizationId() : commonProperties.getOrganizationId();
Map<String, List<String>> connectionHeaders = new HashMap<>();
if (StringUtils.hasText(projectId)) {
connectionHeaders.put("OpenAI-Project", List.of(projectId));
}
if (StringUtils.hasText(organizationId)) {
connectionHeaders.put("OpenAI-Organization", List.of(organizationId));
}
RestClient.Builder restClientBuilder = restClientBuilderProvider.getIfAvailable(RestClient::builder);
WebClient.Builder webClientBuilder = webClientBuilderProvider.getIfAvailable(WebClient::builder);
OpenAiApi openAiApi = OpenAiApi.builder().baseUrl(baseUrl).apiKey(new SimpleApiKey(apiKey)).headers(CollectionUtils.toMultiValueMap(connectionHeaders)).completionsPath(chatProperties.getCompletionsPath()).embeddingsPath("/v1/embeddings").restClientBuilder(restClientBuilder).webClientBuilder(webClientBuilder).responseErrorHandler(responseErrorHandler).build();
AlibabaOpenAiChatModel chatModel = AlibabaOpenAiChatModel.builder().openAiApi(openAiApi).defaultOptions(chatProperties.getOptions()).toolCallingManager(toolCallingManager).retryTemplate(retryTemplate).observationRegistry((ObservationRegistry) observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP)).build();
Objects.requireNonNull(chatModel);
observationConvention.ifAvailable(chatModel::setObservationConvention);
return chatModel;
}
}
com/itheima/ai/model/AlibabaOpenAiChatModel.java
这里就是要用到OpenAIChatModel的底层代码做改写 太长了 可看源文件
改写好以后即可在serviceChatclient里面用自己定义的AlibabaOpenAiChatModel了
SpringAI—ChatPDF-向量模型
4.RAG(知识库 ChatPDF)
由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
- 知识数据比较落后,往往是几个月之前的
- 不包含太过专业领域或者企业私有的数据
为了解决这些问题,我们就需要用到RAG了。下面我们简单回顾下RAG原理
4.1.RAG原理
要解决大模型的知识限制问题,其实并不复杂。
解决的思路就是给大模型外挂一个知识库,可以是专业领域知识,也可以是企业私有的数据。
不过,知识库不能简单的直接拼接在提示词中。
因为通常知识库数据量都是非常大的,而大模型的上下文是有大小限制的,早期的GPT上下文不能超过2000token,现在也不到200k token,因此知识库不能直接写在提示词中。
怎么办?
思路很简单,庞大的知识库中与用户问题相关的其实并不多。
所以,我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了。
那么问题来了,我们该如何从知识库中找到与用户问题相关的内容呢?
可能有同学会相到全文检索,但是在这里是不合适的,因为全文检索是文字匹配,这里我们要求的是内容上的相似度。
而要从内容相似度来判断,这就不得不提到向量模型的知识了。
4.1.1.向量模型
先说说向量,向量是空间中有方向和长度的量,空间可以是二维,也可以是多维。
向量既然是在空间中,两个向量之间就一定能计算距离。
我们以二维向量为例,向量之间的距离有两种计算方法:
通常,两个向量之间欧式距离越近,我们认为两个向量的相似度越高。(余弦距离相反,越大相似度越高)所以,如果我们能把文本转为向量,就可以通过向量距离来判断文本的相似度了。
0.0 把查询文本自己与自己比较,肯定是相似度最高的
1.0722205301828829 把查询文本与其它文本比较【欧氏距离越近相似度越高】
1.0844350869313875
1.1185223356097924
1.1693257901084286
1.14990457630891240.9999999999999998 把查询文本与其它文本比较【余弦距离越远相似度越高】
0.4251716163869882
0.41200032867283726
0.37445397231274447
0.3163386320532005
0.3388597327534832
现在,有不少的专门的向量模型,就可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近:
接下来,我们就准备一个向量模型,用于将文本向量化。
阿里云百炼平台就提供了这样的模型:
这里我们选择通用文本向量-v3,这个模型兼容OpenAI,所以我们依然采用OpenAI的配置。
修改application.yaml,添加向量模型配置:
spring:
application:
name: ai-demo
ai:
ollama:
base-url: http://localhost:11434 # ollama服务地址
chat:
model: deepseek-r1:7b # 模型名称,可更改
options:
temperature: 0.8 # 模型温度,值越大,输出结果越随机
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${OPENAI_API_KEY}
chat:
options:
model: qwen-max # 模型名称
temperature: 0.8 # 模型温度,值越大,输出结果越随机
embedding:
options:
model: text-embedding-v3
dimensions: 1024
4.1.2.向量模型测试
前面说过,文本向量化以后,可以通过向量之间的距离来判断文本相似度。
接下来,我们就来测试下阿里百炼提供的向量大模型好不好用。
首先,我们在项目中写一个工具类,用以计算向量之间的欧氏距离和余弦距离。
[大模型服务平台百炼控制台] (https://bailian.console.aliyun.com/?tab=model#/model-market/detail/text-embedding-v3)
新建一个com.itheima.ai.util包,在其中新建一个类:
package com.itheima.ai.util;
public class VectorDistanceUtils {
// 防止实例化
private VectorDistanceUtils() {}
// 浮点数计算精度阈值
private static final double EPSILON = 1e-12;
/**
* 计算欧氏距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 欧氏距离
* @throws IllegalArgumentException 参数不合法时抛出
*/
public static double euclideanDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double sum = 0.0;
for (int i = 0; i < vectorA.length; i++) {
double diff = vectorA[i] - vectorB[i];
sum += diff * diff;
}
return Math.sqrt(sum);
}
/**
* 计算余弦距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 余弦距离,范围[0, 2]
* @throws IllegalArgumentException 参数不合法或零向量时抛出
*/
public static double cosineDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < vectorA.length; i++) {
dotProduct += vectorA[i] * vectorB[i];
normA += vectorA[i] * vectorA[i];
normB += vectorB[i] * vectorB[i];
}
normA = Math.sqrt(normA);
normB = Math.sqrt(normB);
// 处理零向量情况
if (normA < EPSILON || normB < EPSILON) {
throw new IllegalArgumentException("Vectors cannot be zero vectors");
}
// 处理浮点误差,确保结果在[-1,1]范围内
double similarity = dotProduct / (normA * normB);
similarity = Math.max(Math.min(similarity, 1.0), -1.0);
return similarity;
}
// 参数校验统一方法
private static void validateVectors(float[] a, float[] b) {
if (a == null || b == null) {
throw new IllegalArgumentException("Vectors cannot be null");
}
if (a.length != b.length) {
throw new IllegalArgumentException("Vectors must have same dimension");
}
if (a.length == 0) {
throw new IllegalArgumentException("Vectors cannot be empty");
}
}
}
由于SpringBoot的自动装配能力,刚才我们配置的向量模型可以直接使用。
接下来,我们写一个测试类:
package com.itheima.ai;
import com.itheima.ai.util.VectorDistanceUtils;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.openai.OpenAiEmbeddingModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
class AiDemoApplicationTests {
// 自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
public void testEmbedding() {
// 1.测试数据
// 1.1.用来查询的文本,国际冲突
String query = "global conflicts";
// 1.2.用来做比较的文本
String[] texts = new String[]{
"哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本航空基地水井中检测出有机氟化物超标",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
};
// 2.向量化
// 2.1.先将查询文本向量化
float[] queryVector = embeddingModel.embed(query);
// 2.2.再将比较文本向量化,放到一个数组
List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));
// 3.比较欧氏距离
// 3.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector));
// 3.2.把查询文本与其它文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector));
}
System.out.println("------------------");
// 4.比较余弦距离
// 4.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector));
// 4.2.把查询文本与其它文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector));
}
}
}
🧠 一、什么是“向量化”?
通俗解释:
把一句人类语言(如:“全球冲突”)转换成一个 数字数组(float[]),这个数组可以用于数学运算,比如比较两句话有多相似。
背后用的是 OpenAI 的 embedding 模型(如
text-embedding-3-small),它可以把文本转成固定维度的向量(比如 1536 维的数组)。
🛠 二、如何做到向量化?看关键代码:
java复制编辑@Autowired private OpenAiEmbeddingModel embeddingModel;✅ 这个是 Spring AI 提供的封装:
OpenAiEmbeddingModel是 Spring AI 提供的一个组件,内置了 OpenAI 的嵌入模型调用逻辑。- 实际上它会调用 OpenAI API(如:
/v1/embeddings),将文本变成向量。Spring 会自动帮你完成:
- 构建 HTTP 请求
- 携带 API 密钥
- 接收嵌入向量返回值
- 转成 Java 中的
float[]数组
🧪 代码详细讲解如下:
1. 向量化单个查询文本
String query = "global conflicts"; float[] queryVector = embeddingModel.embed(query);
这行代码背后会调用 OpenAI embedding 接口,把
"global conflicts"变成一个向量,比如:queryVector = [0.123f, 0.456f, ..., 0.789f] // 共1536个 float⚙️ 底层请求类似:
POST /v1/embeddings { "input": "global conflicts", "model": "text-embedding-3-small" }
2. 向量化多个文本
List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));
- 一次性把多个中文文本转成向量。
- 返回的是
List<float[]>,每个文本对应一个向量数组。例如:
texts[0] -> 向量:[0.234f, 0.891f, ...] texts[1] -> 向量:[0.111f, 0.456f, ...]
- 批量处理的好处:效率更高,减少 API 调用次数。
注意: 运行单元测试通用需要配置OPENAI_API_KEY的环境变量
首先,点击单元测试左侧运行按钮:………运行结果:
0.0
1.0722205301828829
1.0844350869313875
1.1185223356097924
1.1693257901084286
1.1499045763089124
------------------
0.9999999999999998
0.4251716163869882
0.41200032867283726
0.37445397231274447
0.3163386320532005
0.3388597327534832
可以看到,向量相似度确实符合我们的预期。
OK,有了比较文本相似度的办法,知识库的问题就可以解决了。
前面说了,知识库数据量很大,无法全部写入提示词。但是庞大的知识库中与用户问题相关的其实并不多。
所以,我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了。
现在,利用向量大模型就可以帮助我们比较文本相似度。
但是新的问题来了:向量模型是帮我们生成向量的,如此庞大的知识库,谁来帮我们从中比较和检索数据呢?
这就需要用到向量数据库了。
4.1.3.向量数据库
主流一线的向量数据库【Milvus】功能全面,支持向量+结构化查询、GPU加速,国内社区活跃
向量数据库的主要作用有两个:
- 存储向量数据
- 基于相似度检索数据
刚好符合我们的需求。
SpringAI支持很多向量数据库,并且都进行了封装,可以用统一的API去访问:
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
这些库都实现了统一的接口:VectorStore,因此操作方式一模一样,大家学会任意一个,其它就都不是问题。
不过,除了最后一个库以外,其它所有向量数据库都是需要安装部署的。每个企业用的向量库都不一样,这里我就不一一演示了。
4.1.3.1.SimpleVectorStore
最后一个SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库,非常适合我们。
我们直接修改CommonConfiguration,添加一个VectorStore的Bean:
@Configuration
public class CommonConfiguration {
@Bean
public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
// ... 略
}
4.1.3.2.VectorStore接口
接下来,你就可以使用VectorStore中的各种功能了,可以参考SpringAI官方文档:
https://docs.spring.io/spring-ai/reference/api/vectordbs.html
这是VectorStore中声明的方法:
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
// 保存文档到向量库
void add(List<Document> documents);
// 根据文档id删除文档
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
// 根据条件检索文档
List<Document> similaritySearch(String query);
// 根据条件检索文档
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}
注意,VectorStore操作向量化的基本单位是Document,我们在使用时需要将自己的知识库分割转换为一个个的Document,然后写入VectorStore.
那么问题来了,我们该如何把各种不同的知识库文件转为Document呢?
4.1.4.文件读取和转换
前面说过,知识库太大,是需要拆分成文档片段,然后再做向量化的。而且SpringAI中向量库接收的是Document类型的文档,也就是说,我们处理文档还要转成Document格式。
不过,文档读取、拆分、转换的动作并不需要我们亲自完成。在SpringAI中提供了各种文档读取的工具,可以参考官网:
https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html#_pdf_paragraph
比如PDF文档读取和拆分,SpringAI提供了两种默认的拆分原则:
PagePdfDocumentReader:按页拆分,推荐使用ParagraphPdfDocumentReader:按pdf的目录拆分,不推荐,因为很多PDF不规范,没有章节标签
当然,大家也可以自己实现PDF的读取和拆分功能。
这里我们选择使用PagePdfDocumentReader。
首先,我们需要在pom.xml中引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
然后就可以利用工具把PDF文件读取并处理成Document了。
我们写一个单元测试(别忘了配置API_KEY):
package com.itheima.ai;
import com.itheima.ai.utils.VectorDistanceUtils;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.openai.OpenAiEmbeddingModel;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
class HeimaAiApplicationTests {
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Autowired
private VectorStore vectorStore;
@Test
public void testVectorStore(){
Resource resource = new FileSystemResource("中二知识笔记.pdf");
// 1.创建PDF的读取器
PagePdfDocumentReader reader = new PagePdfDocumentReader(
resource, // 文件源
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1) // 每1页PDF作为一个Document
.build()
);
// 2.读取PDF文档,拆分为Document
List<Document> documents = reader.read();
// 3.写入向量库
vectorStore.add(documents);
// 4.搜索
SearchRequest request = SearchRequest.builder()
.query("论语中教育的目的是什么") // 查询条件
.topK(1) // 返回的文档数量
.similarityThreshold(0.6) // 阈值 超过的要
.filterExpression("file_name == '中二知识笔记.pdf'") // 过滤条件
.build();
List<Document> docs = vectorStore.similaritySearch(request);
if (docs == null) {
System.out.println("没有搜索到任何内容");
return;
}
for (Document doc : docs) {
System.out.println(doc.getId());
System.out.println(doc.getScore());
System.out.println(doc.getText());
}
}
4.1.5.RAG原理总结
OK,现在我们有了这些工具:
- PDFReader:读取文档并拆分为片段
- 向量大模型:将文本片段向量化
- 向量数据库:存储向量,检索向量
让我们梳理一下要解决的问题和解决思路:
- 要解决大模型的知识限制问题,需要外挂知识库
- 受到大模型上下文限制,知识库不能简单的直接拼接在提示词中
- 我们需要从庞大的知识库中找到与用户问题相关的一小部分,再组装成提示词
- 这些可以利用文档读取器、向量大模型、向量数据库来解决。
所以RAG要做的事情就是将知识库分割,然后利用向量模型做向量化,存入向量数据库,然后查询的时候去检索:
第一阶段(存储知识库):
- 将知识库内容切片,分为一个个片段
- 将每个片段利用向量模型向量化
- 将所有向量化后的片段写入向量数据库
第二阶段(检索知识库):
- 每当用户询问AI时,将用户问题向量化
- 拿着问题向量去向量数据库检索最相关的片段
第三阶段(对话大模型):
- 将检索到的片段、用户的问题一起拼接为提示词
- 发送提示词给大模型,得到响应
4.1.6.目标
好了,现在RAG所需要的基本工具都有了。
接下来,我们就来实现一个非常火爆的个人知识库AI应用,ChatPDF,原网站如下:
这个网站其实就是把你个人的PDF文件作为知识库,让AI基于PDF内容来回答你的问题,对于大学生、研究人员、专业人士来说,非常方便。
当你学会了这个功能,实现其它知识库也都是类似的流程了。
来吧,我们一起动起来!
实现上传下载、记录本次保存时会话ID和文件名的映射关系、把文件写入向量数据库
4.2.PDF上传下载、向量化
既然是ChatPDF,也就是说所有知识库都是PDF形式的,由用户提交给我们。所以,我们需要先实现一个上传PDF的接口,在接口中实现下列功能:
- 校验文件格式是否为PDF
- 保存文件信息
- 保存文件(可以是oss或本地保存)
- 保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件)
- 文档拆分和向量化(文档太大,需要拆分为一个个片段,分别向量化)
另外,将来用户查询会话历史,我们还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
- 读取文件
- 返回文件给前端
4.2.1.PDF文件管理
由于将来要实现PDF下载功能,我们需要记住每一个chatId对应的PDF文件名称。
所以,我们定义一个类,记录chatId与pdf文件的映射关系,同时实现基本的文件保存功能。
先在com.itheima.ai.repository中定义接口:
package com.itheima.ai.repository;
import org.springframework.core.io.Resource;
public interface FileRepository {
/**
* 保存文件,还要记录chatId与文件的映射关系
* @param chatId 会话id
* @param resource 文件
* @return 上传成功,返回true; 否则返回false
*/
boolean save(String chatId, Resource resource);
/**
* 根据chatId获取文件
* @param chatId 会话id
* @return 找到的文件
*/
Resource getFile(String chatId);
}
其中的Rescource是底层提供的class【Spring中表示资源的类】
D:\apache-maven-3.9.5\repository\org\springframework\spring-core\6.2.3\spring-core-6.2.3.jar!\org\springframework\core\io\Resource.class
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.core.io;
import java.io.File;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URL;
import java.nio.channels.Channels;
import java.nio.channels.ReadableByteChannel;
import java.nio.charset.Charset;
import org.springframework.lang.Nullable;
import org.springframework.util.FileCopyUtils;
public interface Resource extends InputStreamSource {
boolean exists();
default boolean isReadable() {
return this.exists();
}
default boolean isOpen() {
return false;
}
default boolean isFile() {
return false;
}
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
default ReadableByteChannel readableChannel() throws IOException {
return Channels.newChannel(this.getInputStream());
}
default byte[] getContentAsByteArray() throws IOException {
return FileCopyUtils.copyToByteArray(this.getInputStream());
}
default String getContentAsString(Charset charset) throws IOException {
return FileCopyUtils.copyToString(new InputStreamReader(this.getInputStream(), charset));
}
long contentLength() throws IOException;
long lastModified() throws IOException;
Resource createRelative(String relativePath) throws IOException;
@Nullable
String getFilename();
String getDescription();
}
再写一个实现类:
package com.itheima.ai.repository;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.time.LocalDateTime;
import java.util.Objects;
import java.util.Properties;
@Slf4j
@Component
@RequiredArgsConstructor
public class LocalPdfFileRepository implements FileRepository {
private final VectorStore vectorStore;
// 会话id 与 文件名的对应关系,方便查询会话历史时重新加载文件
private final Properties chatFiles = new Properties();
@Override
public boolean save(String chatId, Resource resource) {
// 2.保存到本地磁盘
String filename = resource.getFilename();
File target = new File(Objects.requireNonNull(filename));
if (!target.exists()) {
try {
Files.copy(resource.getInputStream(), target.toPath());
} catch (IOException e) {
log.error("Failed to save PDF resource.", e);
return false;
}
}
// 3.保存映射关系
chatFiles.put(chatId, filename);
return true;
}
@Override
public Resource getFile(String chatId) {
return new FileSystemResource(chatFiles.getProperty(chatId));
}
@PostConstruct
private void init() {
// 会话ID映射关系
FileSystemResource pdfResource = new FileSystemResource("chat-pdf.properties");
if (pdfResource.exists()) {
try {
chatFiles.load(new BufferedReader(new InputStreamReader(pdfResource.getInputStream(), StandardCharsets.UTF_8)));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 向量库的持久化 读取
FileSystemResource vectorResource = new FileSystemResource("chat-pdf.json");
if (vectorResource.exists()) {
SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;
simpleVectorStore.load(vectorResource);
}
}
@PreDestroy
private void persistent() {
// 停机时持久化
try {
chatFiles.store(new FileWriter("chat-pdf.properties"), LocalDateTime.now().toString());
SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;
simpleVectorStore.save(new File("chat-pdf.json"));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
注意:
由于我们选择了基于内存的SimpleVectorStore,重启就会丢失向量数据。所以这里我依然是将pdf文件与chatId的对应关系、VectorStore都持久化到了磁盘。
实际开发中,如果你选择了RedisVectorStore,或者CassandraVectorStore,则无序自己持久化。但是chatId和PDF文件之间的对应关系,还是需要自己维护的。
4.2.2.上传文件响应结果
由于前端文件上传需要返回响应结果,我们先在com.itheima.ai.entity.vo中定义一个Result类:
package com.itheima.ai.entity.vo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class Result {
private Integer ok;
private String msg;
private Result(Integer ok, String msg) {
this.ok = ok;
this.msg = msg;
}
public static Result ok() {
return new Result(1, "ok");
}
public static Result fail(String msg) {
return new Result(0, msg);
}
}
4.2.3.文件上传、下载
接下来,我们实现上传和下载文件接口。
在com.itheima.ai.controller中创建一个PdfController:
package com.itheima.ai.controller;
import com.itheima.ai.entity.vo.Result;
import com.itheima.ai.repository.FileRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.Resource;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Objects;
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/pdf")
public class PdfController {
private final FileRepository fileRepository;
private final VectorStore vectorStore;
/**
* 文件上传
*/
@RequestMapping("/upload/{chatId}")
public Result uploadPdf(@PathVariable String chatId, @RequestParam("file") MultipartFile file) {
try {
// 1. 校验文件是否为PDF格式
if (!Objects.equals(file.getContentType(), "application/pdf")) {
return Result.fail("只能上传PDF文件!");
}
// 2.保存文件
boolean success = fileRepository.save(chatId, file.getResource());
if(! success) {
return Result.fail("保存文件失败!");
}
// 3.写入向量库
this.writeToVectorStore(file.getResource());
return Result.ok();
} catch (Exception e) {
log.error("Failed to upload PDF.", e);
return Result.fail("上传文件失败!");
}
}
/**
* 文件下载
*/
@GetMapping("/file/{chatId}")
public ResponseEntity<Resource> download(@PathVariable("chatId") String chatId) throws IOException {
// 1.读取文件
Resource resource = fileRepository.getFile(chatId);
if (!resource.exists()) {
return ResponseEntity.notFound().build();
}
// 2.文件名编码,写入响应头
String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8);
// 3.返回文件
return ResponseEntity.ok()
.contentType(MediaType.APPLICATION_OCTET_STREAM)
.header("Content-Disposition", "attachment; filename=\"" + filename + "\"")
.body(resource);
}
private void writeToVectorStore(Resource resource) {
// 1.创建PDF的读取器
PagePdfDocumentReader reader = new PagePdfDocumentReader(
resource, // 文件源
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1) // 每1页PDF作为一个Document
.build()
);
// 2.读取PDF文档,拆分为Document
List<Document> documents = reader.read();
// 3.写入向量库
vectorStore.add(documents);
}
}
4.2.4.上传大小限制
SpringMVC有默认的文件大小限制,只有10M,很多知识库文件都会超过这个值,所以我们需要修改配置,增加文件上传允许的上限。
修改application.yaml文件,添加配置:
spring:
servlet:
multipart:
max-file-size: 104857600
max-request-size: 104857600
4.2.5.暴露响应头
默认情况下跨域请求的响应头是不暴露的,这样前端就拿不到下载的文件名,我们需要修改CORS配置,暴露响应头:
package com.itheima.ai.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MvcConfiguration implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("Content-Disposition");
}
}
4.3.配置ChatClient
接下来就是最后的环节了,实现RAG的对话流程。
理论上来说,我们每次与AI对话的完整流程是这样的:
- 将用户的问题利用向量大模型做向量化 OpenAiEmbeddingModel
- 去向量数据库检索相关的文档 VectorStore
- 拼接提示词,发送给大模型
- 解析响应结果
不过,SpringAI同样基于AOP技术帮我们完成了全部流程,用到的是一个名QuestionAnswerAdvisor的Advisor。我们只需要把VectorStore配置到Advisor即可。
我们在CommonConfiguration中给ChatPDF也单独定义一个ChatClient:
@Bean
public ChatClient pdfChatClient(
OpenAiChatModel model,
ChatMemory chatMemory,
VectorStore vectorStore) {
return ChatClient.builder(model)
.defaultSystem("请根据提供的上下文回答问题,不要自己猜测。")
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // CHAT MEMORY
new SimpleLoggerAdvisor(),
new QuestionAnswerAdvisor(
vectorStore, // 向量库
SearchRequest.builder() // 向量检索的请求参数
.similarityThreshold(0.5d) // 相似度阈值
.topK(2) // 返回的文档片段数量
.build()
)
)
.build();
}
我们也可以自己自定义RAG查询的流程,不使用Advisor,具体可参考官网:
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
4.4.对话接口
最后,就是对接前端,然后与大模型对话了。修改PdfController,添加一个接口:
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(String prompt, String chatId) {
chatRepository.addChatId("pdf", chatId);
Resource file = fileRepository.getFile(chatId);
return pdfChatClient
.prompt(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId))
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "file_name == '"+file.getFilename()+"'"))
.stream()
.content();
}
5.多模态
多模态是指不同类型的数据输入,如文本、图像、声音、视频等。目前为止,我们与大模型交互都是基于普通文本输入,这跟我们选择的大模型有关。
deepseek、qwen-max等模型都是纯文本模型,在ollama和百炼平台,我们也能找到很多多模态模型。
以ollama为例,在搜索时点击vison,就能找到支持图像识别的模型:
在阿里云百炼平台也一样:
阿里云的qwen-omni模型是支持文本、图像、音频、视频输入的全模态模型,还能支持语音合成功能,非常强大。
注意:
在SpringAI的当前版本(1.0.0-m6)中,qwen-omni与SpringAI中的OpenAI模块的兼容性有问题,目前仅支持文本和图片两种模态。音频会有数据格式错误问题,视频完全不支持。
目前的解决方案有两种:
- 一是使用spring-ai-alibaba来替代。
- 二是重写OpenAIModel的实现,参考第6节
接下来,我们拓展入门时写的对话机器人,让他支持多模态效果。
5.1.切换模型
首先,我们需要修改CommonConfiguration中用于AI对话的ChatClient,将模型修改为OpenAIChatModel,不仅如此,由于其它业务使用的是qwen-max模型,不能改变。所以这里我们还需添加自定义配置,将模型改为qwen-omni-turbo:
com/itheima/ai/config/CommonConfiguration.java
@Bean
public ChatClient chatClient(OpenAiChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model) // 创建ChatClient工厂实例
.defaultOptions(ChatOptions.builder().model("qwen-omni-turbo").build())
.defaultSystem("您是一家名为“黑马程序员”的职业教育公司的客户聊天助手,你的名字叫小黑。请以友好、乐于助人和愉快的方式解答用户的各种问题。")
.defaultAdvisors(new SimpleLoggerAdvisor()) // 添加默认的Advisor,记录日志
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory))
.build(); // 构建ChatClient实例
}
5.2.多模态对话
接下来,我们需要修改原来的/ai/chat接口,让它支持文件上传和多模态对话。
修改ChatController:
package com.itheima.ai.controller;
import com.itheima.ai.repository.ChatHistoryRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.model.Media;
import org.springframework.util.MimeType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.Objects;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
private final ChatHistoryRepository chatHistoryRepository;
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(
@RequestParam("prompt") String prompt,
@RequestParam("chatId") String chatId,
@RequestParam(value = "files", required = false) List<MultipartFile> files) {
// 1.保存会话id
chatHistoryRepository.save("chat", chatId);
// 2.请求模型
if (files == null || files.isEmpty()) {
// 没有附件,纯文本聊天
return textChat(prompt, chatId);
} else {
// 有附件,多模态聊天
return multiModalChat(prompt, chatId, files);
}
}
private Flux<String> multiModalChat(String prompt, String chatId, List<MultipartFile> files) {
// 1.解析多媒体
List<Media> medias = files.stream()
.map(file -> new Media(
MimeType.valueOf(Objects.requireNonNull(file.getContentType())),
file.getResource()
)
)
.toList();
// 2.请求模型
return chatClient.prompt()
.user(p -> p.text(prompt).media(medias.toArray(Media[]::new)))
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId))
.stream()
.content();
}
private Flux<String> textChat(String prompt, String chatId) {
return chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId))
.stream()
.content();
}
}